Beyond OCR: The Future of Document Understanding
DeepSeek OCR uses optical compression technology to analyze complex documents with unparalleled speed and efficiency. From page to data, 10x faster. Supports nearly 100 languages with 97% recognition accuracy.
Experience DeepSeek OCR Live
Upload your images and see how DeepSeek OCR performs in real-time
💡 Tip: This demo is powered by Hugging Face Spaces. Try uploading different types of images to see the OCR capabilities.
Loading DeepSeek OCR Demo...
Powered by Hugging Face Spaces • DeepSeek-AI
Open source • Free to use • No registration required
A Breakthrough in Optical Compression
DeepSeek OCR isn't just another text recognition tool. It's a fundamental rethinking of how machines process visual information, built to be both powerful and lightweight. Using optical compression technology to represent high-resolution documents with a fraction of vision tokens, dramatically reducing computational costs and increasing processing speed.
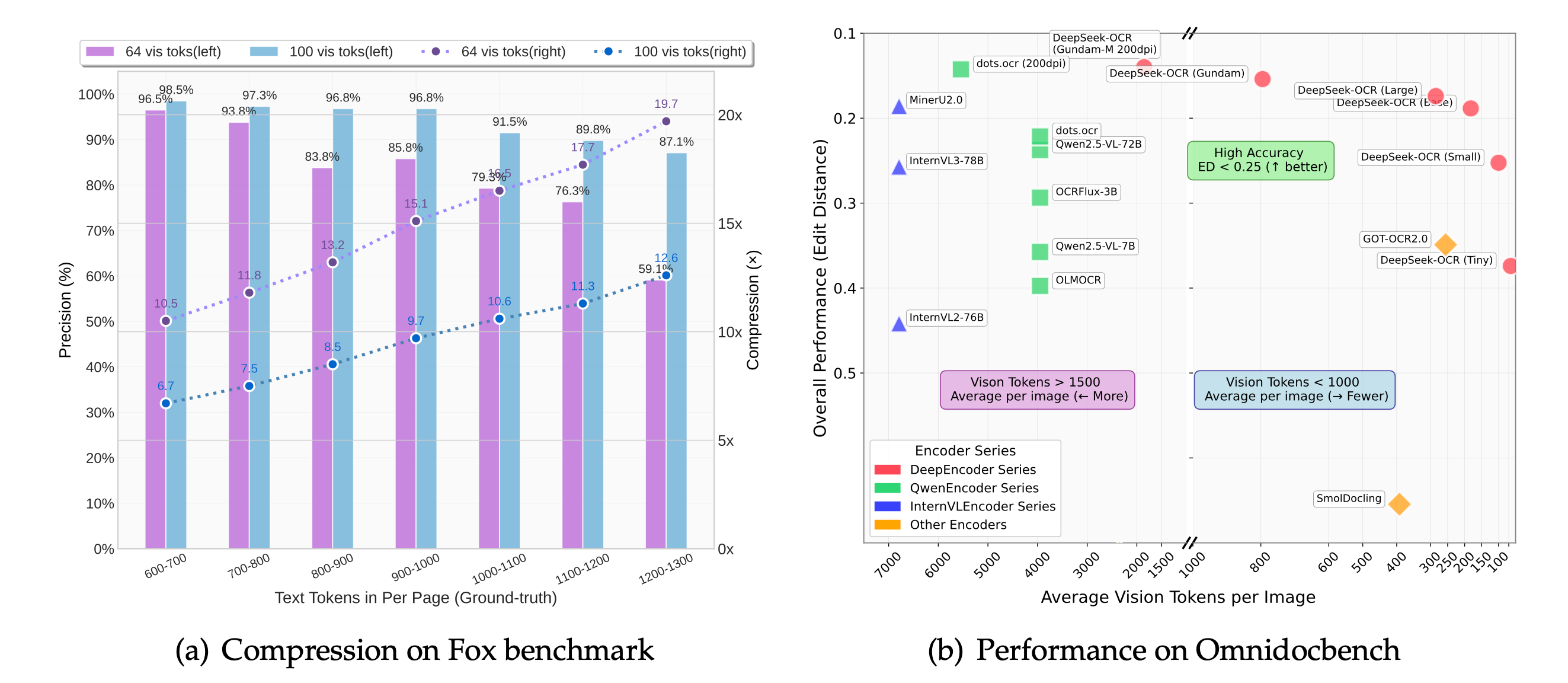
- Ultra-Low Token ConsumptionProcess complete documents with only 100 tokens/page, saving 60% costs compared to GOT-OCR 2.0's 256 tokens. 10-20x compression rate.
- 97% Recognition AccuracyAchieve 97% OCR precision on complex benchmarks. Surpass leading models while using significantly fewer resources.
- Massive Scale ProcessingProcess over 200,000 pages per day on a single GPU, engineered for large-scale data annotation and LLM training.
From Research to Enterprise: Real-World Applications
DeepSeek OCR unlocks new possibilities across industries by making sophisticated document analysis accessible and scalable.



How to Use DeepSeek OCR
Three simple ways to leverage DeepSeek OCR:
Online Tool (Coming Soon)
Upload your image or PDF, get instant OCR results. No installation required. Free tier: 10 conversions/day.

Python API (Transformers)
Install via pip, load the model, and call infer() method. Perfect for simple scripts and prototyping. Supports CUDA for acceleration. Achieve ~2500 tokens/s throughput on a single A100-40G GPU.

Self-Hosted Deployment
Deploy on your own infrastructure for maximum privacy and control. Supports Docker, Kubernetes, and cloud platforms. Minimum: 8GB VRAM (RTX 3070), Recommended: 16GB+ VRAM (RTX 4090, A100-40G).
A Breakthrough in Efficiency and Accuracy
DeepSeek OCR isn't just another text recognition tool, it's a fundamental rethinking of how machines process visual information.
Contexts Optical Compression
The core innovation. We represent high-resolution documents with a fraction of the vision tokens, dramatically reducing computational costs and increasing processing speed. 10-20x compression rate.
State-of-the-Art Accuracy
Achieve up to 97% OCR precision on complex benchmarks. DeepSeek OCR surpasses leading models while using significantly fewer resources.
Versatile Document Parsing
Go beyond plain text. Intelligently extract data from complex layouts, including academic papers, financial charts, chemical formulas, and geometric figures.
Built for Massive Scale
Engineered for real-world deployment, capable of processing over 200,000 pages per day on a single GPU, making it ideal for large-scale data annotation and LLM training.
Global Language Recognition
Trained on a vast dataset covering nearly 100 languages, allowing for accurate text extraction from international documents without changing models.
Low-Memory Architecture
The novel DeepEncoder design processes high-resolution images while maintaining low activation memory, enabling deployment on less powerful hardware and reducing operational costs.
DeepSeek OCR: Frequently Asked Questions
Everything you need to know about DeepSeek OCR - based on official documentation and real-world integration experience.
What is DeepSeek OCR?
DeepSeek OCR is a new vision-language model that specializes in recognizing and extracting text and data from documents using an innovative technique called 'Contexts Optical Compression'. Instead of converting every detail of an image into a large number of tokens, it intelligently compresses the visual information.
What makes 'Contexts Optical Compression' different?
Traditional models require a large number of tokens to represent images, while optical compression technology can represent a complete complex page with 10x fewer data points. This means it can recover 600-1000+ text tokens from just 64-100 vision tokens, making it incredibly fast and efficient.
Is DeepSeek OCR really free and open source?
Yes, 100% open source! The 3B parameter model is available on GitHub (https://github.com/deepseek-ai/DeepSeek-OCR) and Hugging Face with a permissive license. You can: (1) Self-host on your infrastructure (no API costs), (2) Modify the model for your specific needs, (3) Use commercially without licensing fees.
How does this compare to Tesseract and PaddleOCR?
DeepSeek OCR uses a vision-language model (VLM) for context-aware OCR, while Tesseract and PaddleOCR are traditional pattern-matching engines. Key differences: (1) Accuracy: DeepSeek excels at complex documents (tables, formulas, mixed languages) with 97% accuracy vs Tesseract's ~85%. (2) Token efficiency: 100 tokens/page vs PaddleOCR's higher processing overhead. (3) Hardware: Requires GPU (8GB+ VRAM) vs CPU-only for Tesseract. (4) Context understanding: Can correct OCR errors using surrounding text context.
What file types can I analyze?
The underlying model can process a wide range of image formats (PNG, JPEG, WebP) and is particularly effective on pages from PDF documents. The live demo supports direct image uploads and pastes.
What languages does the model support?
The model was trained on a massive dataset covering nearly 100 languages, making it highly effective for multilingual document analysis. Including major languages like Chinese, English, Japanese, etc.
What are the hardware requirements for self-hosting?
GPU requirements: Minimum: 8GB VRAM (RTX 3070, RTX 4060 Ti) for basic inference at ~5-10 pages/min. Recommended: 16GB+ VRAM (RTX 4090, A100-40G) for production at ~100-200 pages/min. Enterprise: Multi-GPU setup (2-4× A100) for 200K+ pages/day. Software: CUDA 11.8+, PyTorch 2.6.0, vLLM 0.8.5+ for optimal throughput. CPU inference is possible but 50-100× slower (not recommended).
Can it understand document structure, not just text?
Absolutely. This is a key strength. It can parse charts into structured data, understand tables, and recognize layouts, converting them into clean formats like Markdown. Perfect for academic papers, financial reports, and other complex documents.
Ready to Experience Next-Gen OCR?
Start using DeepSeek OCR today. Free tier available - no credit card required. Upload your documents and experience 97% recognition accuracy.